
Core Advantages
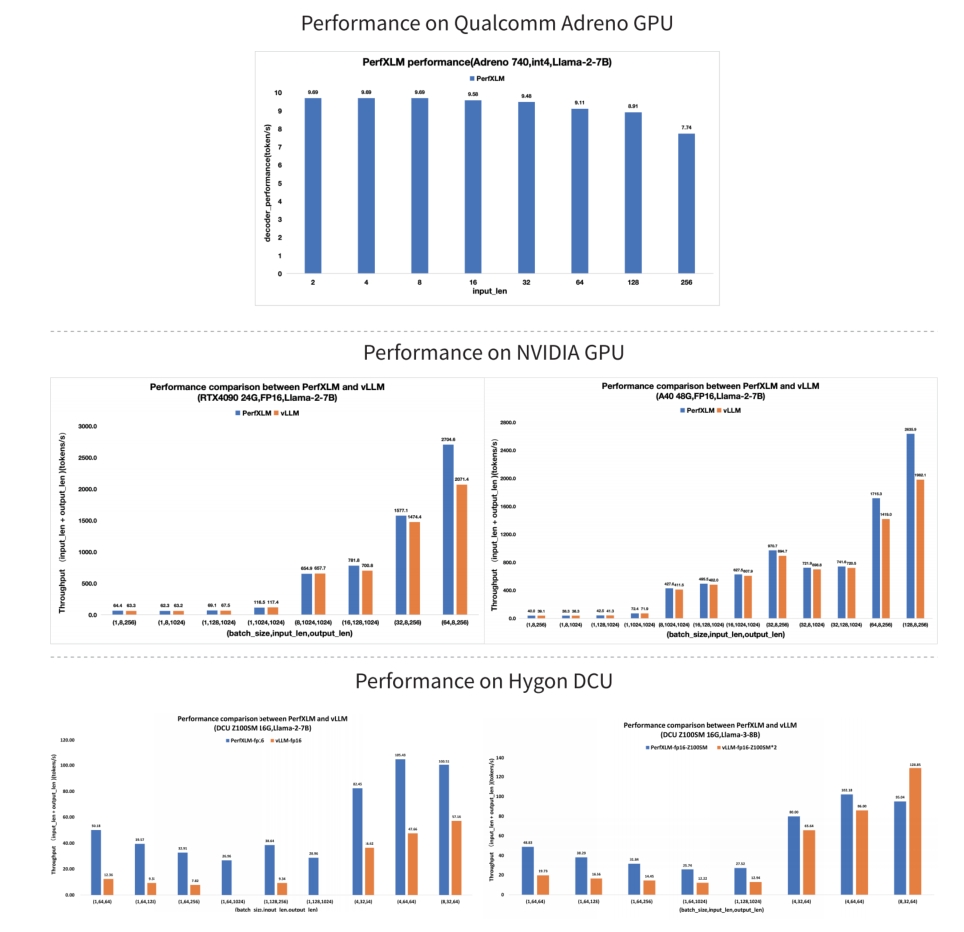
Performance Comparison
Adapted Hardware

PerfXLM is a dedicated large-model inference engine launched by PerfXLab. Its primary aim is to deliver fast adaptation solutions for various mainstream models to different types of heterogeneous hardware. As a powerful inference engine, it not only supports cloud GPU computing power but also is compatible with edge-side lightweight processors. Additionally, it integrates features such as heterogeneous computing support, multi-card parallel processing, and extreme performance optimization. Users can enjoy the convenience and efficiency brought by PerfXLM simply through one-click deployment.